Example running pipeline from script¶
This notebook gives an example of how the package can be used for running it interactively using a notebook.
First, import the package
In [1]:
import dvb.datascience as ds
C:\ProgramData\Anaconda3\lib\site-packages\deap\tools\_hypervolume\pyhv.py:33: ImportWarning: Falling back to the python version of hypervolume module. Expect this to be very slow.
"module. Expect this to be very slow.", ImportWarning)
C:\ProgramData\Anaconda3\lib\importlib\_bootstrap_external.py:426: ImportWarning: Not importing directory C:\ProgramData\Anaconda3\lib\site-packages\mpl_toolkits: missing __init__
_warnings.warn(msg.format(portions[0]), ImportWarning)
C:\ProgramData\Anaconda3\lib\importlib\_bootstrap_external.py:426: ImportWarning: Not importing directory c:\programdata\anaconda3\lib\site-packages\mpl_toolkits: missing __init__
_warnings.warn(msg.format(portions[0]), ImportWarning)
Next, use the package to run the file ‘example.py’ (from the same
directory as this notebook) using the run() method of the example.py
file
In [2]:
p = ds.run_module('example').run()
Experiment started
Running pipeline 1
'Drawing diagram using blockdiag'
Running pipeline 2
'Drawing diagram using blockdiag'
Transform fit
'auc() not yet implemented for multiclass classifiers'
'plot_auc() not yet implemented for multiclass classifiers'
accuracy
| fit |
|---|
| 0.646667 |
mcc
| fit |
|---|
| 0.57563 |
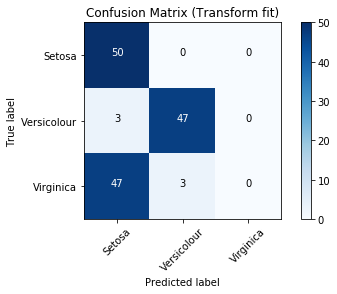
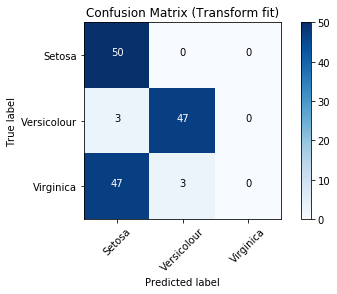
Confusion Matrix
'Precision-recall-curve not yet implemented for multiclass classifiers'
'log_loss() not yet implemented for multiclass classifiers'
Classification Report
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| Setosa | 0.50 | 1.00 | 0.666667 | 50.0 |
| Versicolour | 0.94 | 0.94 | 0.940000 | 50.0 |
| Virginica | 0.00 | 0.00 | 0.000000 | 50.0 |
| avg/total | 0.48 | 0.65 | 0.540000 | 150.0 |
Model Performance

Experiment done